Latest posts
-

Why Am I Sasha Zaitsev – Radio Free Memphis
Ever wonder what it feels like to be a radio pirate in Memphis? Sasha Zaitsev shares his unique journey as the mastermind behind Radio Free Memphis, a pirate radio station disrupting the airwaves. Dive into his world of experimental music, designed to challenge and provoke, and uncover what it truly means to march to the…
-

Fantasy Restaurant Dee Parson
Ever wondered what your ultimate comfort meal would look like if you had no limits? Join me in Dee Parson’s fantasy restaurant, where nostalgia and rebellion serve up a side of spicy popcorn chicken. From childhood influences like Grandma’s canned Pepsi to the ultimate birthday cake handcrafted by a best friend’s mother, Dee’s choice of…
-

Why Am I Brady Drennan – Navel Nuke
What’s life really like when your workplace is a submarine, your family is 120 sailors, and your phone calls home are measured in words instead of minutes? Navy veteran Brady Drennan shares stories from 38 years of service, from fast attack submarines to aircraft carriers, nuclear power, deployment life, leadership, family, and the little pieces…
-

Why Am I Jeffrey Zurek – Volcanologist
On this episode of Why Am I, Greg talks with scientist and podcaster Jeff Zurek about volcanoes, curiosity, public speaking, “type two fun,” and the strange paths that lead us into the work that lights us up. Jeff has a gift for making science feel less like homework and more like an adventure, especially when…
-
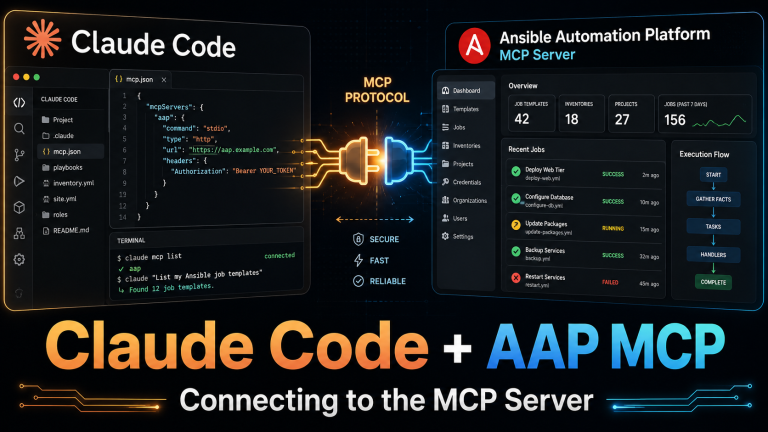
Ansible Automation Platform MCP Server To Claude Code
I’m using AI…you’re using AI…now how do we get it to play with the rest of our tools? MCP is the way my friends. I’m going to cover how I quickly connected my AAP MCP to Claude Code(CC) running on a RHEL 9 VM. I was initially trying to do it via the Windows desktop…
-

Why Am I Rusty Surrette-Alvarez – Life as a News Anchor
On this episode of Why Am I, Greg sits down with Rusty, a Bryan-College Station news anchor who sees journalism less as being on TV and more as helping people feel seen. They talk about curiosity, trust, changing media, social media, Texas pride, and why the best stories usually come from everyday people. Don’t forget…
-

Why Am I Jerry Beck – Cartoon Historian
Jerry Beck has spent a lifetime chasing, preserving, and celebrating the cartoons most people almost forgot. From underground film collecting to restoring classic animation and meeting the legends who made it, this conversation is about obsession, art, nostalgia, and why old cartoons still matter. Don’t forget to like, comment, and subscribe for more conversations that…