Latest posts
-

Fantasy Restaurant Liz Thorpe
Liz puts together an interesting meal…I’ve never eaten fresh clams, but she makes it sound interesting enough to give it a go. One thing I like is that she remember to add atmosphere, which is often forgotten, but always makes a difference. Don’t forget to like, comment, and subscribe for more conversations that chase the…
-

Why Am I Joe Lawther – The Boom Room
Imagine if you will having 60 minutes to free a hostage or perhaps to interrogate the suspect. Your heart is racing, you start sweating…your body is flooding you with adrenalin. Now take a step back and remember that you are in the Boom Room experience created by Joe Lawther. This series of unique experiences are…
-

Fantasy Restaurant Ryan Estrada
What happens when a fantasy meal is built from Amazon coconuts, Himalayan survival snow, train-station samosas, and pumpkin pie blessed by the gods? Ryan Estrada brings wild travel stories, near-death meals, and unforgettable bites to the Fantasy Restaurant. I hope you enjoy this meal as much as I did 🙂 Don’t forget to like, comment,…
-

Why Am I Sean Petrie – Typewriter Rodeo
A man with a 1920s typewriter writes poems for strangers on the spot, and sometimes changes their lives. In this episode of Why Am I, Sean Petrie shares how Typewriter Rodeo turns fleeting moments into something people carry forever. Sean came along right when I need him, and who knows, maybe it’ll be right in…
-

Fantasy Restaurant Fatal1ty
In the warmup for the Why Am I Podcast, the Fantasy Restaurant, anything goes. Fatal1ty builds his ultimate meal, from a vodka soda lime to a filet with a serious green bean backstory. Help us find the perfect beans LOL. Podcast episode on Spotify here. Youtube version here: Please show them some love on their…
-

Fantasy Restaurant Ken Butler
What happens when “anything goes” in a fantasy meal? Ken builds a menu of coconut seltzer, calamari, grilled fish, and a perfectly balanced dessert—while casually revealing he’d eat almost anything. This one gets unexpectedly philosophical (and hungry). Don’t forget to like, comment, and subscribe for more conversations that chase the story behind the person. Podcast…
-
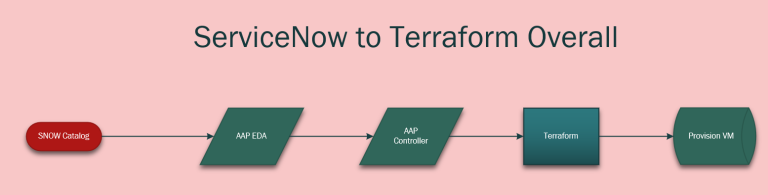
ServiceNow to Terraform via Event-Driven Ansible
This demo shows the dream. A user goes to SNOW’s service catalog, clicks order on a VM, and the Ansible Automation Platform(AAP) calls Terraform to provision. AAP will then configure the server, add it to monitoring, complete any tickets…essentially anything you want to happen. Again, I can’t stress enough how insanely functional this is for…