


Please show them some love on their socials here: https://www.linkedin.com/in/mark-amato-4257b27/, https://www.imdb.com/name/nm0024169/.
If you want to support the podcast you can do so via https://www.patreon.com/whyamipod (this gives you access to bonus content including their Fantasy Restaurant!)

Whether for security reasons(you don’t want hosts connecting directly to internet) and/or for efficiency reasons(uses less of your internet connection), it’s often valuable to create a local repository for your Rocky packages. In short, keep a local copy of all the Rocky packages you use so that your servers will just pull from there instead of the internet.
You can do that manually via this useful article here, or you can do it via automation as shown here using ansible playbooks and ascender.
You need a Rocky host with access to the internet, a webserver running on it, and the rsync utility. If you have the Rocky host, this automation can not only setup the rsync, but it can also install and configure the webserver if you like.
Demo Video
Playbook
All of my assets can be found here.
There’s a playbook and a few templates.
I’ll break the playbook down portions of the playbook below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | vars:
# path to webserver directory to hold all files
web_path: /var/www/local-repo
# path to where scripts and script data should be stored
script_path: /opt/scripts
# how frequent in hours to sync repo
sync_hours_freq: 4
# would you like to install and configure an nginx webserver
configure_webserver: true
# configure selinux for webserver folder storing repo files
selinux_config: true
# sync the repo immediately instead of waiting for standard time interval
sync_now: false
# exclude objects from repository sync
# this list was kindly supplied by Jimmy Conner
repo_exclude:
- '*/Devel*'
- '*/Live*'
- '*/aarch64*'
- '*/ppc64le/*'
- '*/s390x/*'
- '*/kickstart/*'
- '*/source/*'
- '*/debug/*'
- '*/images/*'
- '*/isos/*'
- '*/live/*'
- '*/Devel*'
- '8/*'
- '8.4/*'
- '8.5/*'
- '8.6/*'
- '9/*'
- '9.0/*' |
First I’m setting up several variables. The path variables are pretty straightforward; where do you want things stored. The playbook will actually make sure those paths exist, and then place said files based on the templates in the templates folder.
The sync_hours_freq variable sets how often the cronjob that does the rsync runs. I’ve currently got it set to 4 hours, which should be pretty solid.
The configure_webserver variable(if set to true) will install an Nginx webserver, setup its config file, and configure the firewall to allow access to the server.
selinux_config: true will configure the selinux settings for the web root folder if a configure_webserver is also set to true.
sync_now will(when set to true) start the rsync immediately instead of waiting for the standard interval.
Last, the repo_exclude variable will set up a list of objects in the remote repository to ignore when performing the rsync. The current list was created by my teammate Jimmy Conner, so be sure to thank him.
The remainder of the playbook is pretty straightforward and well documented, so I’ll skip discussing it here.
Conclusion
There are a LOT of benefits to running a local repo, and running this playbook(on average) takes about 40 seconds…so what are you waiting for? Granted, while the playbook runs quickly, it does take a little while for the rsync to complete, but should have its initial run completed in less than a couple hours. After that, updates will move fairly rapidly. As always, please reach out with any questions or comments.
Happy automating and repo-ing!

Please show them some love on their socials here: https://www.linkedin.com/in/mark-amato-4257b27/, https://www.imdb.com/name/nm0024169/.
If you want to support the podcast you can do so via https://www.patreon.com/whyamipod (this gives you access to bonus content including their Fantasy Restaurant!)
AWX derivatives are great tools for putting enterprise controls around your automation. Ascender brings the best of open source automation into one easy-to-install package, and now when you are ready to migrate from either AWX or Red Hat’s Ansible Automation Platform (AAP), you can with a few simple steps. It doesn’t stop there, though. You can migrate portions of your dev/test Ascender installs over to production, or simply use them as templates for Configuration As Code (CAC). The materials here will be showing how to do a 1 to 1 migration, but in the near future, I’ll be creating and demoing some interesting use cases for distribution across your enterprise.
Video Demo
Playbooks
All of my materials can be found here in my public repository.
I’m also using a few collections and tools:
Community.general – Used for some json_query filtering.
Controller_configuration – Awesome RH COP collection of roles used to interact with the awx.awx collection.
Awx.awx – Modules designed to easily interact with the API. This is already baked into the default Ascender EE.
Awxkit – A Python CLI tool for interacting with the API. This too is already baked into the default Ascender EE.
I’m going to break them into two categories: ones used for exporting information and those used for importing information.
Exporting
The primary file is export.yml. I’m not going to walk through every piece; rather, I’ll cover the important bits… or maybe those where I think I’m being particularly clever. 😉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | hosts: save-files
vars:
# These are the objects you wish to export. Be sure to comment out any you don't want.
export_objects:
- applications
- credentials
- credential_types
- execution_environments
- inventory
- inventory_sources
- job_templates
- notification_templates
- organizations
- projects
- schedules
- teams
- users
- workflow_job_templates |
First is the host section. Here I have a server that will act as a temporary file repository. Future versions will be saving all of these files to a git repository, but for now I wanted it to be as quick and simple as possible. So choose a server that can hold a few KB of files.
Next is the export_objects variable in the vars section. Any items in this list that aren’t commented out will be exported into their yaml formatted configuration file (then stored on the save-files host).
1 2 3 4 5 | environment:
CONTROLLER_HOST: "https://{{ export_host }}"
CONTROLLER_USERNAME: "{{ gen1_user }}"
CONTROLLER_PASSWORD: "{{ gen1_pword }}"
CONTROLLER_VERIFY_SSL: False |
The awx.awx collection uses these environment variables to authenticate and connect to the API of the server that will be exporting data. You can set these variables in the vars section, hard code them here, or like me, you can securely pass them in from Ascender!
Once the export is complete, I copy these files into my repository in a directory named “configs.”
Importing
There was a LOT more work that had to be done on the import side. In fact, this is where I spent the majority of my dev time. There is a lot of formatting of variables, filtering of information, reconfiguring of variable structures, or outright creation of variables that had to be done… and lucky for you, it should just work now!
The primary file for importing information is import.yml. Again, I’ll only cover the important bits here, though all of my tasks have comments and descriptions.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # These are the objects you want to import into the server.
export_objects:
- testing_value
- applications
- credentials
- credential_types
- execution_environments
- projects
- inventory
- inventory_sources
- job_templates
- notification_templates
- organizations
- teams
- users
- workflow_job_templates
- schedules |
This is the exact same variable from the export.yml file. It defines what sections should be imported.
1 2 3 4 | # Add hosts and or groups when adding/updating inventories
# By default inventories won't import hosts/groups, so setting these variables will control that.
add_hosts: true
add_groups: true |
When you import an inventory, it only creates the inventory, which means none of the hosts or groups within it are imported. If you want those to be imported also, you modify these two variables. By default they are set to true, so if you import an inventory, then the hosts and groups will come along with it.
1 2 3 4 | # These are the users that won't be imported. Recall these users will have their passwords and keys wiped.
# I'm using the admin user for importing so I want to ignore it.
filter_user_import:
- admin |
When importing users, it’s often desirable to exempt some users. When user accounts are imported, their passwords, keys, etc. are wiped. I’m using the admin account for importing, so I exempt it.
1 2 3 4 5 6 7 | # List of schedule names to remove when importing.
# By default I'm removing all of the system defaults
schedules_to_remove:
- 'Cleanup Job Schedule'
- 'Cleanup Activity Schedule'
- 'Cleanup Expired Sessions'
- 'Cleanup Expired OAuth 2 Tokens' |
When importing some schedules, you may want to ignore some. In my case, I’m removing any of the system defaults from the import (they will already be in the other host).
1 2 3 4 5 | environment:
CONTROLLER_HOST: "https://{{ import_host }}"
CONTROLLER_USERNAME: "{{ gen2_user }}"
CONTROLLER_PASSWORD: "{{ gen2_pword }}"
CONTROLLER_VERIFY_SSL: False |
As in the export.yml file, you must set up the environment variable information here for the host you plan to import configurations to.
Once you hit the task section, we are entering what I call the “modification” section. This is where I do massive cleanup first to the variable files (just the copy in the Execution Environment (EE)). Some changes were easier to fix in the variable files before they were brought into memory.
Then all of the variable files are imported into memory, and after that another big round of cleanup/manipulation is done to the variables.
1 2 3 4 5 6 7 8 9 10 11 12 13 | ####### start importing various information
- name: block and rescue for multiple attempts
block:
- name: Add credential types
when: item == "credential_types"
ansible.builtin.include_role:
name: credential_types
loop: "{{ export_objects }}"
rescue:
- name: Add credential types - second attempt
ansible.builtin.include_role:
name: credential_types |
Last, we enter the importing section. This is where all of the data is actually pushed into the remote host.
You can see I use a block and rescue for each one of the tasks. Essentially, I just call the relevant role and it will push in the data using an asynchronous method, which means it fires multiple tasks in the background so that they will complete as quickly as possible. It then checks the status for each. This definitely speeds up the import process.
I noticed that hammering the API in this fashion also leads to failures when importing a lot of information at once. It’s for this reason I went with a block and rescue. If the initial attempt fails for some of the imports, it will then rerun the exact same role, and in my testing this usually does the trick.
Configure Ascender, AWX, or AAP
I won’t be doing the step-by-step here… if you are migrating automation platforms, I assume you already know how to add a project and create a job template. I will show you my simple modifications.
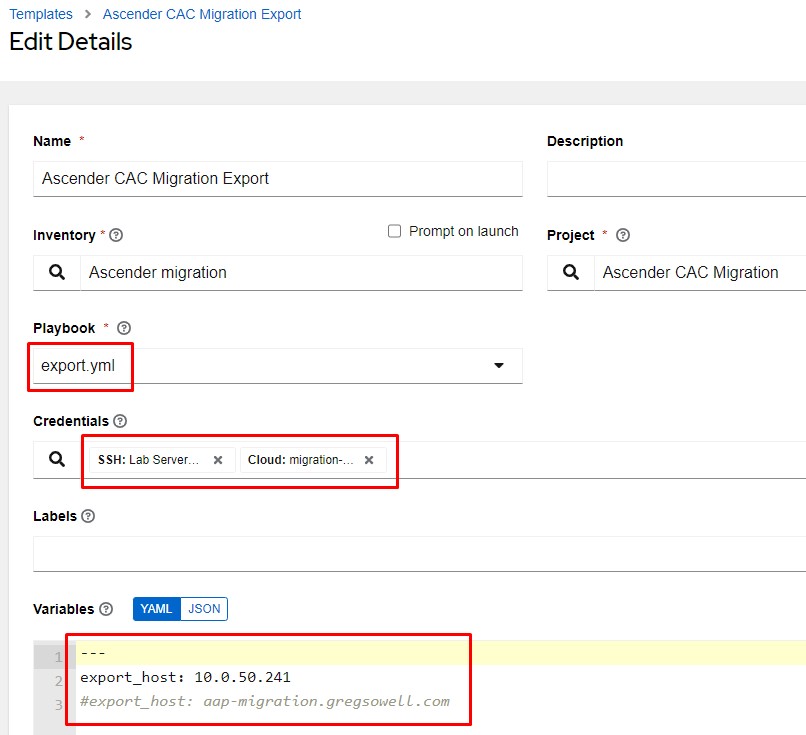
In the above example, I’m configuring the export playbook.
I created a custom credential that supplies the gen1_user and gen1_pword values.
I also added the machine credential to connect to my save-files host that will be holding the configs as they are created.
In the variables section, I’m adding the IP or Fully Qualified Domain Name(FQDN) of the host I’ll be connecting to and exporting info out of.
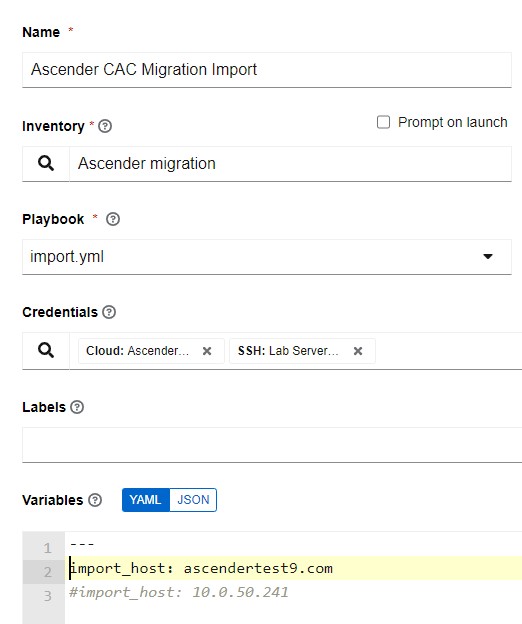
In this screenshot, I’m configuring the import job template.
Again, I have a custom credential that in this instance supplies gen2_user and gen2_pword.
Last in the variables section, I specify the import_host FQDN or IP address. This will be the host I’m pushing all of the configurations to.
Caveats
Passwords aren’t exported; therefore, they aren’t imported. If you are using a secrets engine, then this is a moot point as all of the private information is looked up at automation execution time.
This isn’t exporting or configuring specific Ascender configurations like: logging, authentication, etc. Right now it’s only (mostly) pulling/pushing configurations specific to automation. I plan to continually expand this, though.
Roles aren’t imported at this time (the awx.awx collection isn’t bringing that in).
User accounts aren’t currently optimally imported if you are also using an external authentication system. It will try and use the local account first before attempting external auth, so if it is imported manually, this can cause issues. You can either not import users or have all of your users login once to the new system first.
Conclusion
This is, perhaps, the most impactful automation I’ve created to date. I hope you can use it to test drive Ascender, or maybe just improve your backups 🙂.
This is V1.0 of this automation, so know that it isn’t yet in its final evolution. I implore you to let me know how I can improve it (again, I have very interesting variations on this that are coming soon). If you find bugs (I can’t test every scenario), please let me know, or contribute code if you can.
Thanks and happy migrating!

Please show them some love on their socials here: GASP…he doesn’t use socials LOLOL
If you want to support the podcast you can do so via https://www.patreon.com/whyamipod (this gives you access to bonus content including their Fantasy Restaurant!)

Please show them some love on their socials here: https://spiritualpathcoaching.com/, https://www.instagram.com/spiritualpathcoaching/.

Please show them some love on their socials here: https://spiritualpathcoaching.com/, https://www.instagram.com/spiritualpathcoaching/.